Als je deze blog in de gaten hebt gehouden, zul je misschien merken dat de Kubernetes-applicatie die ik aan het bouwen ben, bijna af is. Nou, ik ben blij je te kunnen zeggen dat dit inderdaad klopt. In de vierde week van mijn stage heb ik een applicatie bestaande uit meerdere onderdelen volledig kunnen migreren naar een Kubernetes Cluster.
Absoluut niet, deze eerste migratie heeft me veel van de Kubernetes-wereld geleerd. De grootste les die ik heb geleerd is dat de mogelijkheden met Kubernetes eindeloos zijn. Dit project was een goede reis om mij de basisprincipes van Kubernetes te leren en mij de weg te laten volgen om een “Kubernetes-held” te worden.
Geen paniek, dit zal niet de laatste blogpost zijn, want mijn Kubernetes-strijd zal doorgaan met de volgende applicatie die klaar is voor migratie. Dat klopt, het doel van deze stage is om drie volledig werkende applicaties te migreren naar één enkele Kubernetes Cluster, dus voor nu hebben we eentje gedaan, met nog twee te gaan.
Aangezien dit de grootste toepassing van de drie was, wat betekent dat het de meeste componenten bevatte, was het een hele uitdaging om deze te migreren, dus ik ben wel blij dat ik verder kan gaan met een nieuw project. Ik heb nog steeds het gevoel dat ik je een laatste afscheid van dit project verschuldigd ben.
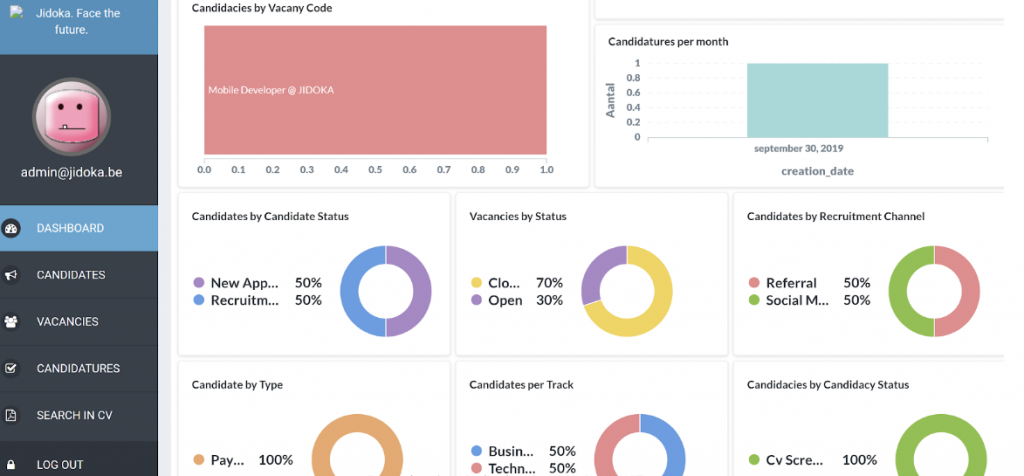
Op het eerste gezicht is dit dashboard misschien niet zo duidelijk over wat het probeert over te brengen, maar ik zal mijn best doen om het uit te leggen.
Op dit dashboard kun je de belangrijkste statistieken over de vacatures en kandidaturen van de geregistreerde profielen bekijken. Je kunt je afvragen over welke vacatures en kandidaturen ik het heb. Deze applicatie is in principe een rekruteringstool waarbij kandidaten en openstaande vacatures worden verzameld en gecombineerd. Het is een tool die intern in het bedrijf gebruikt wordt om profielen te koppelen aan passende vacatures.
Na het afronden van alle details van deze Kubernetes implementatie, heb ik een week vakantie genomen omdat het ook een deel van mijn stage is. Gedurende deze week heb ik mijn hoofd leeggemaakt en heb ik een pauze genomen van een aantal van de taken van mijn stage. Ik heb wat tijd met vrienden doorgebracht en genoten van mijn kleine pauze terwijl ik mijn energie weer opbouwde om de volgende uitdaging aan te gaan.
Nu zal de trend in deze blog zich voortzetten aangezien mijn volgende applicatie ook een hulpmiddel is dat intern wordt gebruikt. Ik zal voorlopig niet veel informatie over de applicatie onthullen, maar in de volgende blogberichten krijg je waarschijnlijk wel wat hints over wat voor soort tool het is. Net als de rekruteringstool ben ik begonnen met het bouwen van de implementaties van de backend, om te zeggen dat dit een onverwachte start had was een licht understatement. Een belangrijk onderdeel van Kubernetes is het feit dat alle implementaties gebaseerd zijn op Docker-images. Toen ik erachter kwam dat de backend van deze applicatie ook gebaseerd was op een Spring boot-applicatie, was ik een beetje opgelucht, omdat het ook betekende dat de implementatie veel leek op mijn vorige Spring boot-implementatie. Helaas was ik achteraf niet zo opgelucht omdat ik er ook achter kwam dat er nog geen Docker image beschikbaar was van deze applicatie.
Ik had ergere problemen tijdens deze reis, dus het opbouwen van een Docker-image vanuit een Spring boot-applicatie kon niet zo moeilijk zijn. Gelukkig was dat niet zo. Na overleg met Jan had ik genoeg aanwijzingen gekregen om een goede start te maken met deze applicatie. Omdat de Spring boot-applicatie een Gradle project is, was het zo eenvoudig als het definiëren van een Jib plugin in het bouwbestand en een paar minuten later had ik een werkende Docker-image naar onze Nexus repository gestuurd. Was elke taak in deze stage maar zo eenvoudig als deze.
Na een tijdje had ik een volledig functionerende Spring Boot-implementatie van de 2e applicatie draaien. Dit verliep soepel omdat het veel leek op de eerste applicatie. De volgende stap zou het uitrollen van de database zijn. Om het een beetje interessant te maken was de database voor deze applicatie een MongoDB-database. Ik had een beetje voorkennis van MongoDB, dus ik dacht dat ik geen problemen zou hebben met het implementeren van dit onderdeel. De implementatie van de database ging vrij gemakkelijk, er was niet veel configuratie nodig en het was vrij eenvoudig. Precies hetzelfde als de Angular implementatie.
Na de implementatie moet ik de database vullen met enkele initiële gegevens, zodat ik inloggegevens zou hebben om toegang te krijgen tot de applicatie. Het lijkt niet zo moeilijk, maar ik ben een hele dag bezig geweest om uit te zoeken hoe ik een dump van de database kan importeren in de Kubernetes MongoDB. Ik heb zelfs de hulp gevraagd van Maarten, een ontwikkelaar die aan de interne applicatie werkt, om me te helpen brainstormen over dit probleem. Net als toen Frodo en Sam bezig waren met het beklimmen van de Mount Doom, waren ik en Maarten bezig met het beklimmen van stackoverflow-threads op zoek naar een antwoord. We probeerden elke mogelijke vlag van het mongorestore commando uit te testen, maar helaas was dit tevergeefs. Aan het einde van de dag, toen we bijna wilden opgeven, merkte ik een klein probleempje op in het pad van de dump file, waardoor we het uiteindelijk toch werkende hebben gekregen. De interne applicatie had zich gevuld met inloggegevens terwijl Maarten en ik aan het juichen waren alsof we net de ring in Mount Doom hadden gegooid.
De laatste paar weken waren echt de moeite waard, want ik slaagde erin om een applicatie volledig af te werken, en tegelijkertijd heb ik ook bijna een tweede applicatie af. Het laat me ook merken dat mijn stage bijna halverwege is. De leercurve is steil maar leuk geweest en ik kan niet wachten op mijn volgende uitdaging.
Copyright 2025 JIDOKA BV, Motstraat 30, B-2800 Mechelen, BE 0543.452.396, RPR Antwerpen



