
Eind november vorig jaar organiseerde JIDOKA een hackathon van vrijdagavond na het werk tot zondag in de late namiddag. Samen met 2 collega’s vormde ik 1 van de 7 teams die deelnamen. Het onderwerp dat we hebben gekozen is iets waar bijna elke developer ter wereld één of ander probleem mee heeft: timesheets. Dus No time left!

Ik denk dat we het er allemaal over eens zijn dat geen enkel gezond persoon op deze aarde graag timesheets invult, maar dat ze een noodzakelijk kwaad zijn. Zolang er maar één timesheetsysteem is om te gebruiken en je maar een beperkt aantal taken hebt om tijd op te boeken is het meestal wel te doen. Maar als er meerdere timesheetsystemen zijn of als je veel verschillende taken hebt om de tijd te registreren wordt het al snel een probleem om deze informatie goed en op tijd bij te houden en de systemen synchroon te laten lopen.
Timesheetsystemen
In het geval van JIDOKA zijn er 2 timesheetsystemen: Atlassian Jira (met de Tempo plugin) en Harvest.

De eerste, Jira, wordt gebruikt voor projectmanagement en bevat de projecten/tickets waar we als developers aan werken. We loggen alle tijd die we aan een bepaald ticket hebben besteed. De Tempo-plugin combineert al deze worklogs in een medewerkerstimesheet die maandelijks kan worden ingediend. Dit systeem wordt vooral gebruikt door het developmentteam om bij te houden wat er aan een project is gedaan en door wie. Maar ook om te rapporteren over de voortgang van het project.
Het tweede systeem, Harvest, wordt vooral gebruikt door projectmanagers, het managementteam en de financiële afdeling om projectbudgetten te volgen en facturen te versturen.
Beide systemen houden in principe de tijd bij, maar op een andere manier, met een verschillend niveau van verfijning. Beide moeten worden gesynchroniseerd door de gebruiker die de worklogs maakt. Dit veroorzaakt een hoop problemen:
- ticket/project/taak aan één of beide zijden bestaat niet
- de gebruiker heeft geen toegang tot een ticket/project/taak aan één of beide zijden
- gemakkelijk om fouten te maken terwijl de tijd die is gelogd van het een op het andere systeem in kaart wordt gebracht
- geen goede correlatie tussen systemen
- …
Het eindresultaat is dat er veel wrijving is. Timesheets die niet op tijd worden ingevuld en timesheets die niet synchroon lopen. Er zijn ook developers die zich afvragen wat de zin van het leven is. En inschatten of timesheets hetgeen is dat ze het meest haten aan hun job.

Doel
Dus besloot ons team om er iets aan te doen. Het doel was om het systeem zo te verbeteren dat de developers slechts in het ene systeem de tijd zouden moeten registreren en dat het andere systeem automatisch gesynchroniseerd zou worden. We zijn immers IT-professionals en het automatiseren van alledaagse taken is waar we voor leven. Met zo’n systeem zouden we zowel het management/de financiële afdeling als onze developers tevreden kunnen houden. Zo ontstond de titel: No time left! (what’s in a name)

Team en metholodogie
Ons team bestond uit drie mensen:
- Twee developers (inclusief mezelf) waarvan 1 met een affiniteit voor frontend-ontwikkeling en de andere voor backend-ontwikkeling
- 1 analist/PM (respect voor hem om op een hackathon te zijn!)
De eerste dag, of beter gezegd avond, was een vrijdag na het werk waar we eerst naar de locatie moesten rijden waar de hackathon werd gehouden. Dit betekende dat we maar een paar uur hadden voordat we wat slaap nodig hadden. Omdat onze analist/PM net terug was van een “Agile Project Management”-cursus, besloten we toe te passen wat hij geleerd had.
Dus de uren erna spendeerden we aan de volgende taken:
- Het exacte probleem definiëren dat we wilden oplossen
- De verschillende manieren definiërendie kunnen worden gebruikt om het probleem op te lossen
- Snel wat onderzoek en POC’s doen om deze oplossingen te evalueren/beoordelen
- Hier hebben we snel gecontroleerd welke bestaande applicaties/plugins/API’s bestaan die ons zouden kunnen helpen
- Op basis van deze informatie beslissen welke oplossing wordt toegepast
- Een actieplan opstellen en het werk verdelen
We hebben uiteindelijk gekozen voor de volgende aanpak:
- De Jira ticket interface uitbreiden zodat de persoon die de tickets maakt deze eenvoudig kan koppelen aan een Harvest projecttaak.
- Creëer een centrale component die worklogs kan verzamelen uit meerdere bronnen (waaronder Jira) en die veranderingen (aanmaken/updaten/verwijderen) zal doorgeven naar meerdere doelsystemen (waaronder Harvest ).
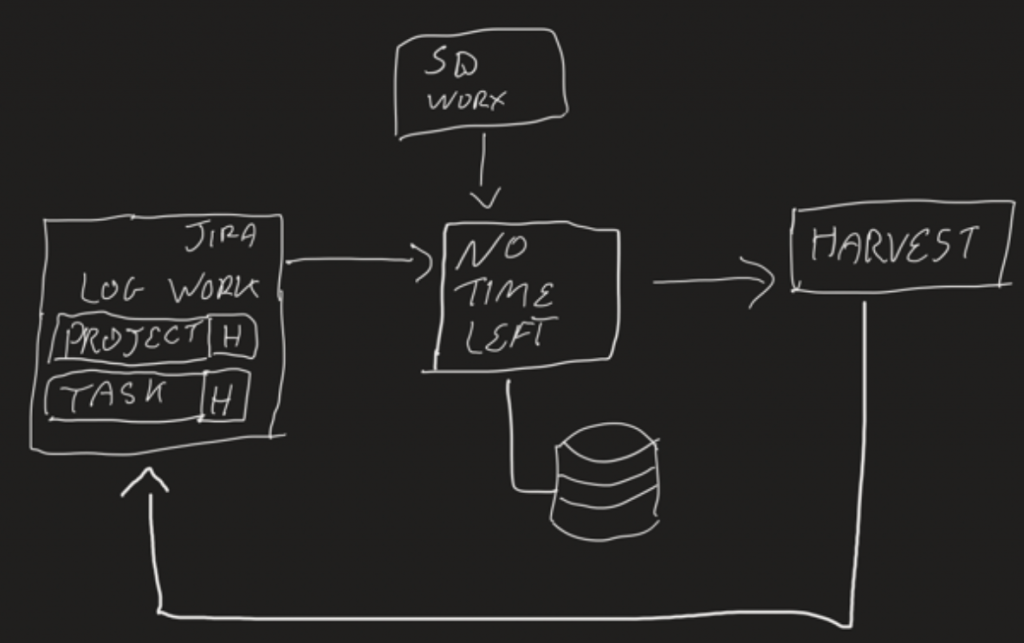
Technologie en oplossing
Vanwege de beperkte duur van de hackathon hebben we besloten om de zaken simpel te houden en dicht bij de technologie te blijven die JIDOKA intern gebruikt. We hebben ook een paar shortcuts genomen, zoals geen frontend creëren voor de centrale component en het gebruik van een vaste user mapping tussen het bron- en doelsysteem.
Voor de Jira-kant hebben we de uitstekende Elements Connect plugin gebruikt. Met deze plugin kunnen we de Harvest v2 REST API gebruiken om een gegevensbron te definiëren die we vervolgens kunnen gebruiken om twee gekoppelde aangepaste velden te maken. Deze worden dan gevuld met alle beschikbare projecten en hun taken. De twee aangepaste velden kunnen dan in Jira worden geconfigureerd om op elk ticket te verschijnen. Zo kan een projectmanager per ticket definiëren waar de tijd zou kunnen worden gesynchroniseerd in Harvest.
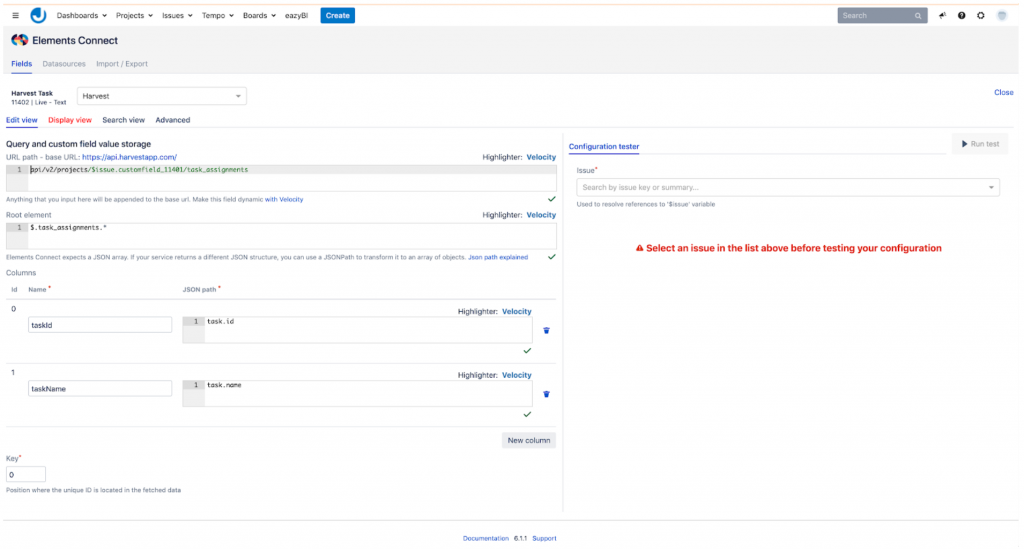
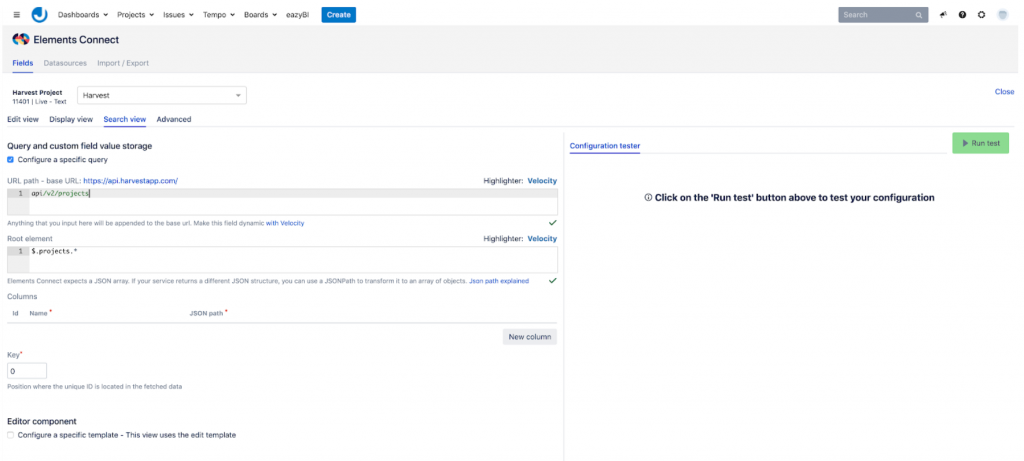
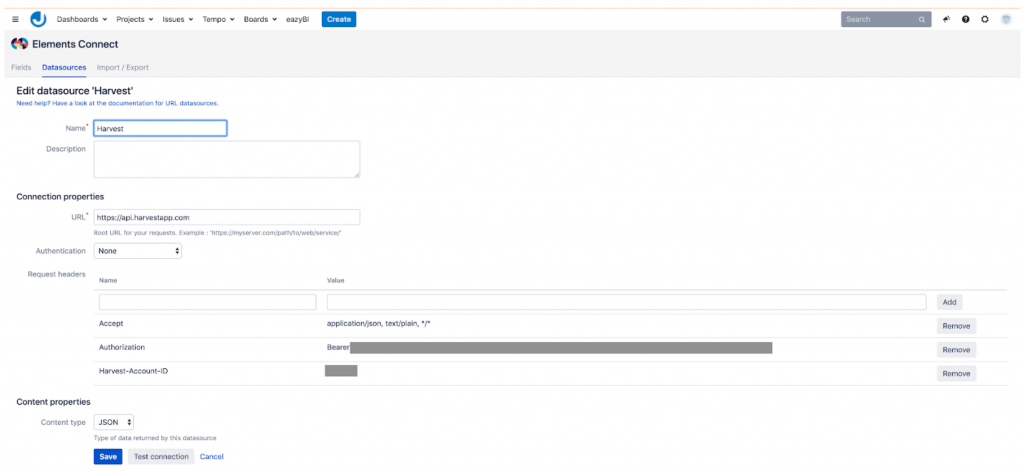
Time sync-component
Voor de Time sync-component hebben we standaard Spring Boot 2.x en gebruiken we OpenFeign om snel met de Jira en Harvest API’s te kunnen communiceren. Daarnaast hebben we het scheduling part van Spring Boot gebruikt om jobs te creëren die de tijdsbronnen voor nieuwe worklogs opvragen. En die ze zal opslaan met behulp van Spring Boot Data in een PostgreSQL-database. Een tweede job wordt dan uitgevoerd die de juiste wijzigingen zal aanbrengen op de doelsystemen.
We hebben een klein domein gemodelleerd in de Time sync-component dat zich centreert rond TimeChunks. Een TimeChunk is een generieke weergave van de tijd die wordt besteed aan iets wat zich in Jira vertaalt naar een worklog. We hebben ook een TimeChunkCorrelation-klasse toegevoegd. Dit zal ons genoeg informatie geven om de link tussen een TimeChunk in een doelsysteem en hetzelfde in het bronsysteem te kunnen volgen. Voor de hackathon is dit gedaan door de ID’s bij te houden die in beide systemen worden gebruikt.
Door de gekozen oplossing hoeven er geen wijzigingen te worden aangebracht in de doelsystemen, alleen in Harvest in dit geval. Dit komt omdat we alleen met hen communiceren door gebruik te maken van hun API’s. Dus het enige wat we nodig hebben is een geldige set referenties of een token die we kunnen gebruiken om de API’s te gebruiken.
Uiteindelijk hebben we het grootste deel van het systeem aan de praat gekregen. Het was, op enkele randgevallen na, functioneel voor de Jira-naar-Harvest combinatie voor het toevoegen/updaten/verwijderen.

Conclusie
- Timesheets zullen altijd klote blijven. Maar we moeten de timesheets zo gemakkelijk en gebruiksvriendelijk mogelijk maken, zelfs als er meerdere systemen/formaten nodig zijn
- Er is geen OOTB-systeem dat doet wat wij willen
- De Harvest en Jira API’s zijn misschien niet altijd het duidelijkst, maar alles wat we nodig hadden om er toegang toe te krijgen, was toegankelijk.
- De Element Connect-plugin voor Jira was een serieus werk om correct te laten functioneren voor gerelateerde velden. Maar het werkte perfect op het einde
- Spring Boot is ongeveer zo low-code als het maar kan op de Java-kant voor een tijd beperkte hackathon als deze
- Het volgen van een methodiek/plan in een hackathon heeft zijn waarde, net als voldoende slaap
PS.: we zijn nu een nieuwe methode aan het testen waarbij we geen tijd meer registreren in Jira, alleen nog in Harvest. Om de voortgang van het project te kunnen volgen, doet Jira speciale dingen met de cyclustijd. Dit zou moeten volstaan voor onze PM’s.






