
In onze eerste blogpost rond CQRS/ES hebben we kort dit architecturaal patroon toegelicht, de specifieke project context geschetst waarin we ons bevonden en zijn we ook ingegaan in de specifieke redenen die ons tot dit patroon hebben geleid.
In deze blogpost gaan we dieper in op de technische details en hoe we CQRS/ES hebben toegepast in dit legacy systeem.
Chose boring technologies
In 2016 volgde ik een DDD & CQRS cursus bij Greg Young en 1 van de adviezen die hij daar gaf was: gebruik geen framework om CQRS met ES te gebruiken, je kan zelf gemakkelijk met een beperkte hoeveelheid code een ES systeem opzetten door gebruik te maken van een RDMBS met een batch job die als “poor man’s queue” fungeert.
Je kan je laten inspireren door het Simple CQRS voorbeeld project (geschreven in C#) op Greg Young’s GitHub pagina: https://github.com/gregoryyoung/m-r
Als je begint met ES is het vooral belangrijk om je te focussen op de voordelen qua modellering, de infrastructurele set-up is eigenlijk van minder belang en je raakt vaak heel ver door bewust voor “saaie” technologie te kiezen, je hebt echt geen nieuwe frameworks of bijvoorbeeld Kafka nodig om ES te doen.
Dat is ook exact wat we in onze spike deden om te proberen om de belangrijkste aggregate in ons bestaande legacy systeem te event sourcen, concreet zag dit qua design er zo uit:
Architectuur overview
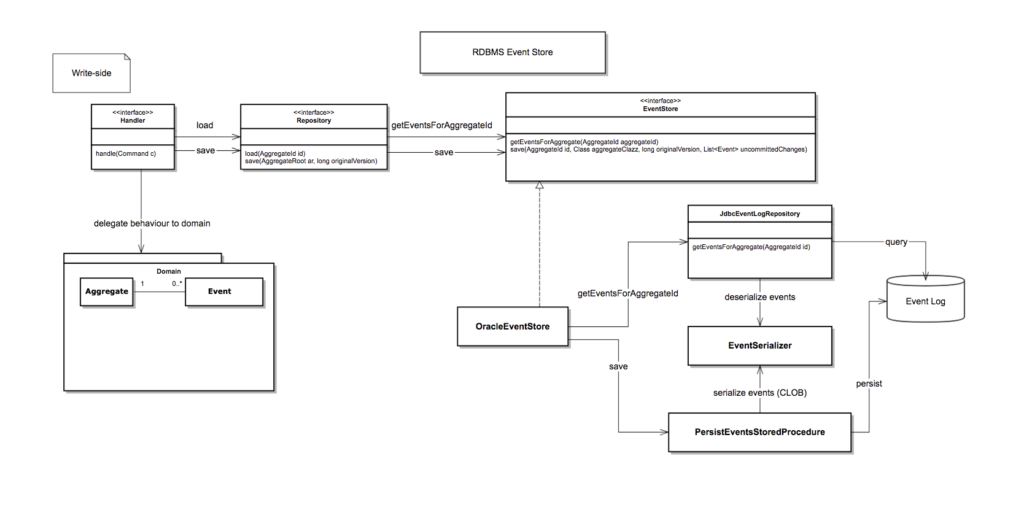
Merk op dat de “PersistentRepository” de events wegschrijft als JSON in een Oracle database tabel, de enige verplichte velden die in elk event moeten zitten zijn de volgende:
| Attribuut naam | Toelichting |
|---|---|
| ID (UUID) | Een event uniek identificeren, handig voor debugging redenen en om idempotentie in te bouwen aan de leeskant |
| Version | Voor optimistic locking, elke individuele aggregate begint zijn eerste event met 0, daarna 1, etc. (vergelijkbaar met het “version” veld in een ORM) |
| Name | De naam van het event |
| AggregateID | De specifieke aggregate waartoe het event behoort, als de huidige state van de aggregate moet worden opgebouwd worden alle events met dezelfde aggregate id in de juiste volgorde opnieuw afgespeeld |
| De specifieke attributen van het event |
Toen deze spike een succes leek en we besliste dit te implementeren was één van de belangrijkste oefeningen het hermodeleren van de aggregate, dit verhaal is out of scope voor deze blogpost maar ik wil hier wel herhalen dat het erg belangrijk is je ook erg goed nadenkt over de events zelf, welke domein events moet je registeren, hoe moeten ze heten (de DDD ubiquitous language!), hun attributen, etc.
Zorg er voor dat dit zeker een team effort is en dat je hierin ook business analysten en domein experten betrekt.
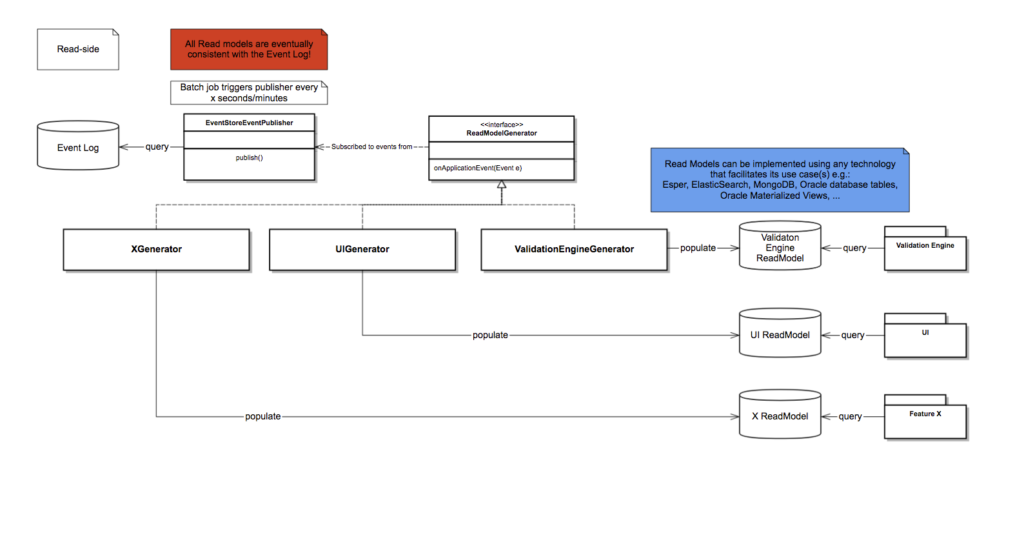
Aangezien we in een legacy systeem werkte gebruikte we voor de events te publishen geen externe queue maar een simpele Spring batch job die elke paar seconde liep en een configureerbaar aantal events op een in-memory queue zette.
Het voordeel van dit zo te doen was dat dit heel simpel te implementeren was en omdat het systeem monolitisch bleef ook niet al de complexiteit van een gedistribueerd systeem in het project te trekken.
Het nadeel is natuurlijk dat het systeem monolitisch blijft en dat deze set-up dus maar beperkt schaalbaar is. Dit was echter geen concern in dit project aangezien de schaalbaarheid van de monoliet tot nog toe geen probleem was geweest en de schaal waarop de applicatie moest kunnen werken goed gekend was. Geen constraint in de context van dit specifieke project dus maar your mileage may vary!
Lessons learned
- De donkere kant van event sourcing: versionering van events, dit is een complex topic, zo complex zelfs dat Greg Young er een heel boek over aan het schrijven is. 1 gouden tip is om zeker genoeg aandacht te spenderen aan het modelleren van de events en ze echt als een onderdeel van het domein model te beschouwen.
- Een andere trade-off die we initieel niet hadden voorzien: Door ES toe te passen win je flexibiliteit bij het modelleren van je domain model. Het domein model bestaat alleen in-memory en kan je relatief eenvoudig, zonder data migraties, aanpassen en bijsturen omdat enkel de events persistent zijn. Maar dit wil natuurlijk wel zeggen dat de events zelf moeilijk te veranderen zijn!
- Onderschat de complexiteit van CQRS en ES niet, gebruik het alleen als het nodig is en als het past in de specifieke context waarin je je bevind, ik vroeg ook tijdens de cursus aan Greg Young wanneer hij het zelf niet zou gebruiken en zijn antwoord was duidelijk: als je met een simpele CRUD applicatie genoeg hebt kan je beter met Transactie Scripts en een ORM werken.
- Geen nieuwe frameworks introduceren om CQRS/ES te doen was een goede keuze, je hebt weinig “infrastructure” code nodig om een simpele event store te bouwen boven op een RDMBS met een batch job, dit zorgt er ook voor dat het aantal nieuwe dingen die je met je team moet leren beperkt blijft.
Resources
- Greg Young’s boek over versioning in een event sourced systeem
- Choose boring technology






