

Lang geleden kwam in een JIDOKA kantoorruimte niet zo ver weg een bepaald idee tot leven na een interessante discussie met het JIDOKA DevOps team. Het idee bestond uit de mogelijkheid om een Kubernetes-cluster op Azure te bouwen met als enig doel om als testomgeving te fungeren voor enkele van onze interne toepassingen. Niet het grootste en meest creatieve idee zou je denken, maar we herinnerden ons dat we een gecentraliseerde Sentry applicatie op onze Elastic Kubernetes cluster draaiende hebben. De Sentry-applicatie wordt gebruikt om log data te verzamelen van onze productie-applicaties en om onze developers te verwittigen als er nieuwe onbekende problemen opduiken. Onze testomgeving wordt voortdurend gebruikt door programmeurs om nieuwe functies en nieuwe versies van bepaalde componenten te testen.
Het zou nuttig zijn voor de programmeurs die het nu gebruiken als ze ook de logboeken van de testapplicaties zouden kunnen zien om er zeker van te zijn dat ze klaar zijn om de incubatieperiode te verlaten en te veranderen in vlinders, of productie-applicaties, wat u ook verkiest.
Let op voor het grote slechte internet!
Het grootste gevaar in dit verhaal is de beveiliging van data. De logboeken kunnen gevoelige gegevens bevatten die we niet via het internet naar Sentry willen sturen. De oplossing hiervoor zou zijn om de Azure Kubernetes-Cluster te verbinden met de Amazone Kubernetes-Cluster via een redundante VPN verbinding. Met deze aanpak hebben we een veilige manier om gevoelige data tussen twee Kubernetes-clusters te sturen. De eerste use case die we vonden waren de Sentry-logs. Maar dit zouden we verder kunnen uitbreiden door ook Vault-secrets op te halen. Database verbindingen en kunnen op deze manier ook beter beveiligd worden. Gecentraliseerde services als Elasticsearch, kunnen nu ook over meerdere clusters gedeeld worden, de lijst is eindeloos.
D to the N to the S
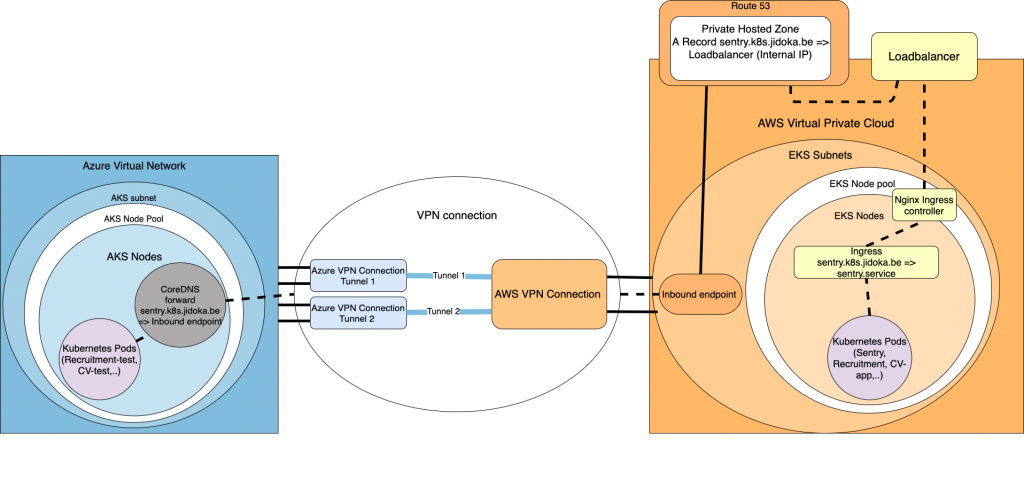
Nadat het ons gelukt was om beide virtuele cloud-netwerken met elkaar te verbinden, blijven we nog steeds zitten met het probleem van DNS. De levenscyclus van Kubernetes-pods is vaak hetzelfde als die van een eendagsvlieg, wat het kortst levende dier op aarde is. De beestjes hebben een gemiddelde levensduur van slechts 24 uur. Zeg nu niet dat je niets geleerd hebt door deze blog te lezen. Dit maakt routering op basis van IP niet mogelijk omdat ze vaak vernieuwd worden. In de wetenschap dat al onze diensten onder een specifieke hostnaam werken, kunnen we de DNS-oplossing op de Azure-cluster configureren om specifieke requests door te sturen naar de Amazon-Cluster. Hierna krijgen zij de taak om de DNS-request af te handelen, terwijl de Azure-cluster afwacht op een antwoord die de juiste route bevat.
Route53 to the rescue!
Een eerste stap om dat te realiseren, zou zijn om een DNS forward lookup zone in CoreDNS toe te voegen. CoreDNS is de standaard DNS-server die door de meeste Kubernetes-clusters wordt gebruikt. In de lookup zone definiëren we de hostnaam van de dienst die we willen bereiken op het Amazon-cluster. Maar naar waar stuurt deze lookup zone de aanvragen door?
Hier brengt Route53 ons redding. Door Route53 te gebruiken kunnen we een privaat gehoste zone definiëren en deze koppelen aan de VPC van het Amazon-cluster. Deze privaat gehoste zone zal enkel fungeren als een dienst om alle aanvragen die van het Inbound endpoint komen, te verwijzen naar de loadbalancer van de cluster. Om Route53 te bereiken voor DNS-oplossing, zullen we een Inbound endpoint creëren in hetzelfde subnet van de Amazon-cluster. Dit Inbound endpoint vangt alle inkomende verzoeken die via de VPN-tunnel binnenkomen. Verder laat het de verzoeken door de privaat gehoste zone afhandelen. Vergeet niet om het Inbound-endpoint een IP te laten creëren in elk subnet van je Amazon-cluster.
Om de DNS-server op Azure te verbinden met het inbound endpoint, definiëren we de forward lookup zone om alle aanvragen voor onze hostnaam door te sturen naar de IP’s van het inbound endpoint. Nu al onze verzoeken uiteindelijk worden doorgestuurd naar het interne IP van de loadbalancer, worden ze doorgestuurd naar de Ingress controller en via de Ingress naar de juiste service verholpen. Dit lijkt misschien allemaal een beetje ingewikkeld, maar hopelijk kan het volgende plaatje je helpen de flow te begrijpen. In dit voorbeeld sturen we alleen de Sentry-hostnaam door naar de Amazon-cluster. In theorie zou je een wildcard hostnaam in de CoreDNS configuratie kunnen zetten, en één in de private gehoste zone als een A record, om meer hostnamen van de Amazon-cluster te verhelpen.
Difficult difficult lemon difficult
Waarom doen we eigenlijk al die moeite? We kunnen toch ook gewoon met twee Amazon-clusters werken? Op die manier zouden we toch minder problemen hebben met routing en DNS? Ten eerste: de kennis die we opdoen door producten te gebruiken van andere cloudaanbieders. Dit zorgt ervoor dat we onze expertise verbreden en onze klanten meer mogelijkheden bieden.
Ten tweede: bij JIDOKA zijn we niet bang voor een uitdaging. We zien deze situatie als een leermogelijkheid in plaats van een omweg voor ons probleem. Daarnaast zijn enkele van de functies en producten van Azure interessant voor onze use case, waaronder de loadbalancer-implementatie. Het geïntegreerde kostenbesparend systeem van Azure stelt ons ook in staat om een kleinere en meer kosteneffectieve testomgeving te gebruiken.
Was het de moeite waard?

Het heeft gelukkig niet alles gekost, een goede hoeveelheid onderzoek in combinatie met de juiste ‘can-do’ mentaliteit is genoeg om deze omgeving te reproduceren. De ervaring die we hebben opgedaan met deze uitdaging maakte de problemen en de vele kopzorgen de moeite waard.






